Project Overview
Sälka Designs is a small business looking to streamline their production process by automating their production schedule and bill of materials (BOM). The goal was to create an automated, cloud-based pipeline that would ingest order data from Squarespace e-commerce and generate weekly reports for the production team.
Business Value:
- Eliminated 3-5 hour weekly manual process
- Reduced human error in data extraction and formatting
- Enabled proactive inventory management through automated BOM reports
Architecture Overview
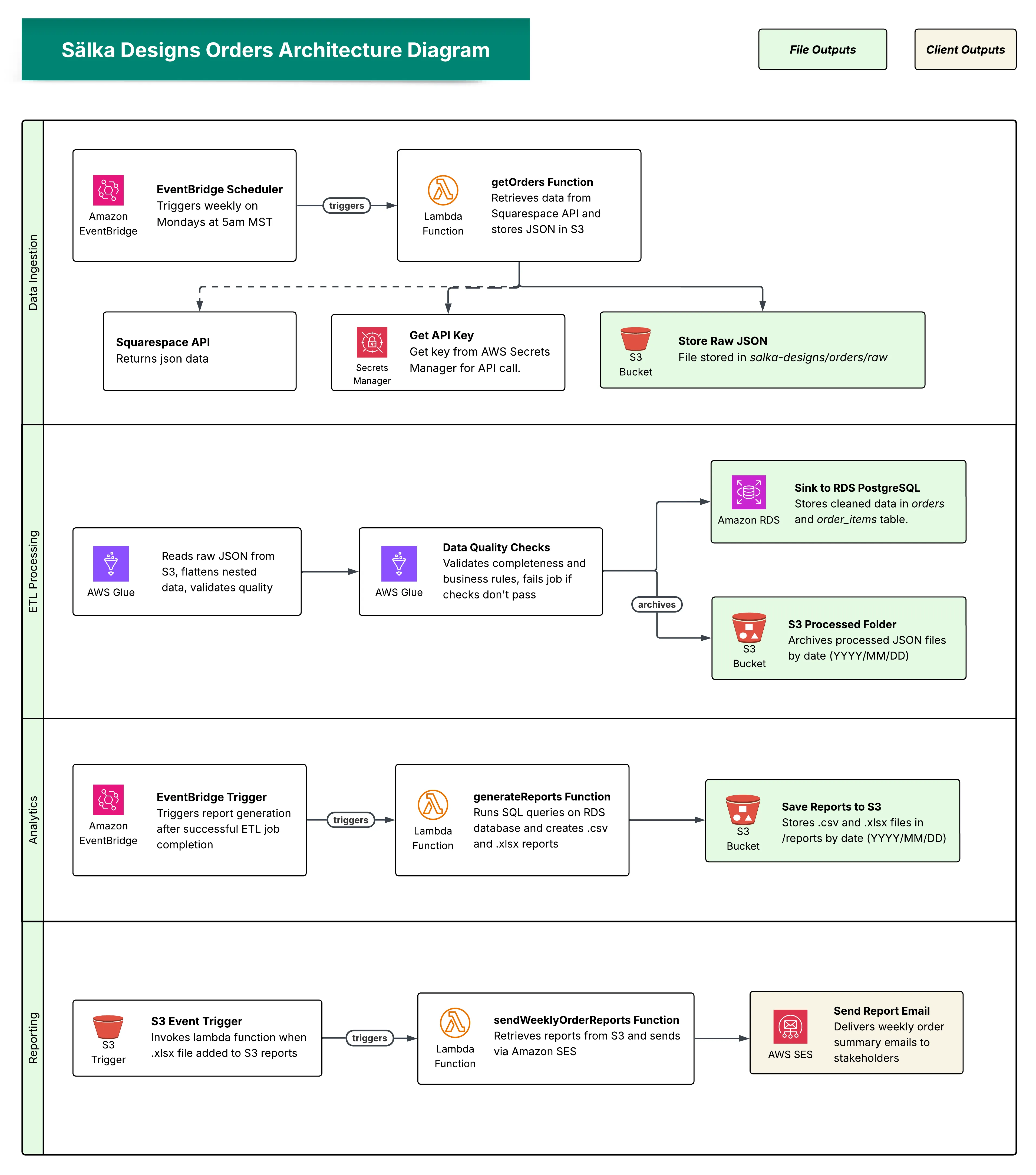
Event-driven pipeline with four main steps:
- Data Ingestion - Automated data extraction from Squarespace API
- ETL Processing - Data transformation, quality validation, and storage
- Analytics - Report generation from cleaned data
- Reporting - Automated email delivery to stakeholders
Technologies: AWS Lambda, AWS Glue, Amazon RDS (PostgreSQL), Amazon S3, Amazon EventBridge, Amazon SES, AWS Secrets Manager, VPC, Python, SQL, Pandas
Data Ingestion Layer
The pipeline begins with automated data collection every Monday at 5am MST using Amazon EventBridge Scheduler, which triggers the getSalkaOrders Lambda function.
Key Features:
- Retrieves Squarespace API credentials from AWS Secrets Manager
- Stores complete JSON responses in S3 with timestamped filenames
- Automatically triggers ETL processing via Glue job
- Lambda function role is limited to required resources (S3 bucket, starting Glue job)
def lambda_handler(event, context):
try:
timestamp = datetime.now().strftime("%m%d%Y_%H%M%S")
raw_orders_key = f"orders/raw/squarespace_orders_{timestamp}.json"
# Step 1: Get raw orders from Squarespace API
raw_orders_data = get_squarespace_orders()
# Step 2: Save raw JSON data to S3
s3_file_location = save_json_to_s3(raw_orders_data, RAW_DATA_BUCKET, raw_orders_key)
# Step 3: Trigger Glue job to process the raw data
glue_job_run_id = run_glue_job()
return {
'statusCode': 200,
'body': json.dumps({
'message': 'Raw Squarespace API data saved',
'orders_count': len(raw_orders_data.get('result', [])),
'glue_job_run_id': glue_job_run_id
})
}
except Exception as e:
print(f"Error: {str(e)}")
return {'statusCode': 500, 'body': json.dumps({'error': str(e)})}ETL Processing Layer
Why AWS Glue?
I chose AWS Glue after evaluating several AWS options. AWS DataBrew cannot handle complex nested JSON structures or load directly into PostgreSQL. Athena could query the JSON files, but would need additional tools for database loading. Glue offered the right balance: automatic JSON transformation, direct PostgreSQL connection, and pay-per-use pricing.
JSON Flattening with SparkSQL:
The core transformation handles nested JSON structures using SparkSQL’s explode function with lateral view to maintain original row data:
SELECT
order.id as order_id,
order.orderNumber as order_number,
order.createdOn as created_on,
order.customerEmail as customer_email,
CONCAT(order.shippingAddress.firstName, ' ', order.shippingAddress.lastName) as customer_name,
order.fulfillmentStatus as fulfillment_status,
COALESCE(CAST(order.grandTotal.value AS NUMERIC), 0) AS order_total,
lineItem.sku as product_sku,
lineItem.productName as product_name,
lineItem.quantity as product_quantity,
COALESCE(lineItem.variantOptions[0].value, 'Default') as product_color
FROM order_data
LATERAL VIEW explode(result) exploded_orders AS order
LATERAL VIEW explode(order.lineItems) exploded_items AS lineItemData Quality Validation:
DataQualityChecks_ruleset = """
Rules = [
RowCount > 0,
Completeness "order_id" = 1.0,
Completeness "customer_email" = 1.0,
Completeness "product_quantity" = 1.0,
ColumnValues "product_quantity" > 0,
ColumnValues "product_price" >= 0
]
"""Database Design
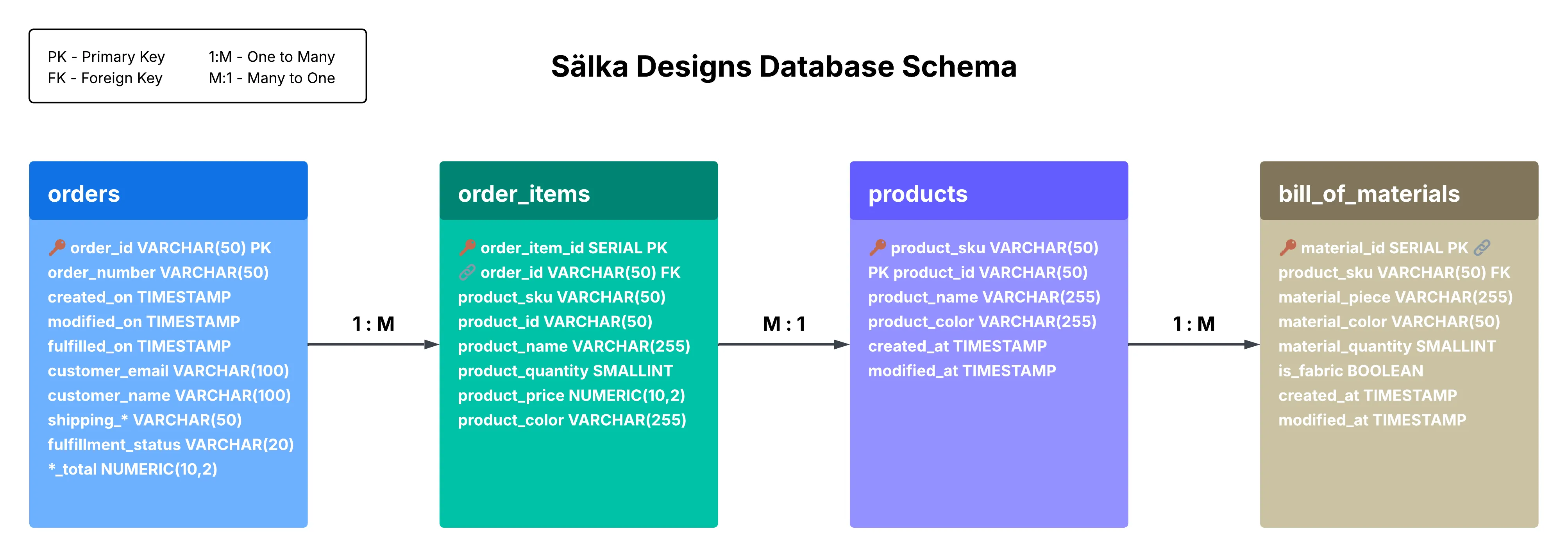
The database implements a four-table design modeling the complete production workflow for customer orders and required materials.
Handling Delta Updates:
Orders need to reflect status changes throughout production. I used a staging table approach with a stored procedure for upserts:
CREATE OR REPLACE FUNCTION upsert_orders_from_staging()
RETURNS INTEGER AS $$
DECLARE
rows_affected INTEGER := 0;
BEGIN
INSERT INTO orders (order_id, order_number, created_on, modified_on, ...)
SELECT order_id, order_number, created_on, modified_on, ...
FROM temp_orders_staging
ON CONFLICT (order_id) DO UPDATE SET
modified_on = EXCLUDED.modified_on,
fulfilled_on = EXCLUDED.fulfilled_on,
fulfillment_status = EXCLUDED.fulfillment_status;
GET DIAGNOSTICS rows_affected = ROW_COUNT;
RETURN rows_affected;
END;
$$ LANGUAGE plpgsql;Incremental Processing for Order Items:
To reduce processing overhead, I use timestamp-based incremental loading:
def get_max_date_from_database():
max_date_query = """
SELECT COALESCE(MAX(o.created_on), '1900-01-01'::timestamp) as max_date
FROM order_items oi
JOIN orders o ON oi.order_id = o.order_id
"""
return spark.read.option("query", max_date_query).load().collect()[0]['max_date']
# Only process order items newer than last successful run
last_processed_timestamp = get_max_date_from_database()
new_order_items_df = order_items_df.filter(col("created_on") > last_processed_timestamp)Network Security & VPC Configuration
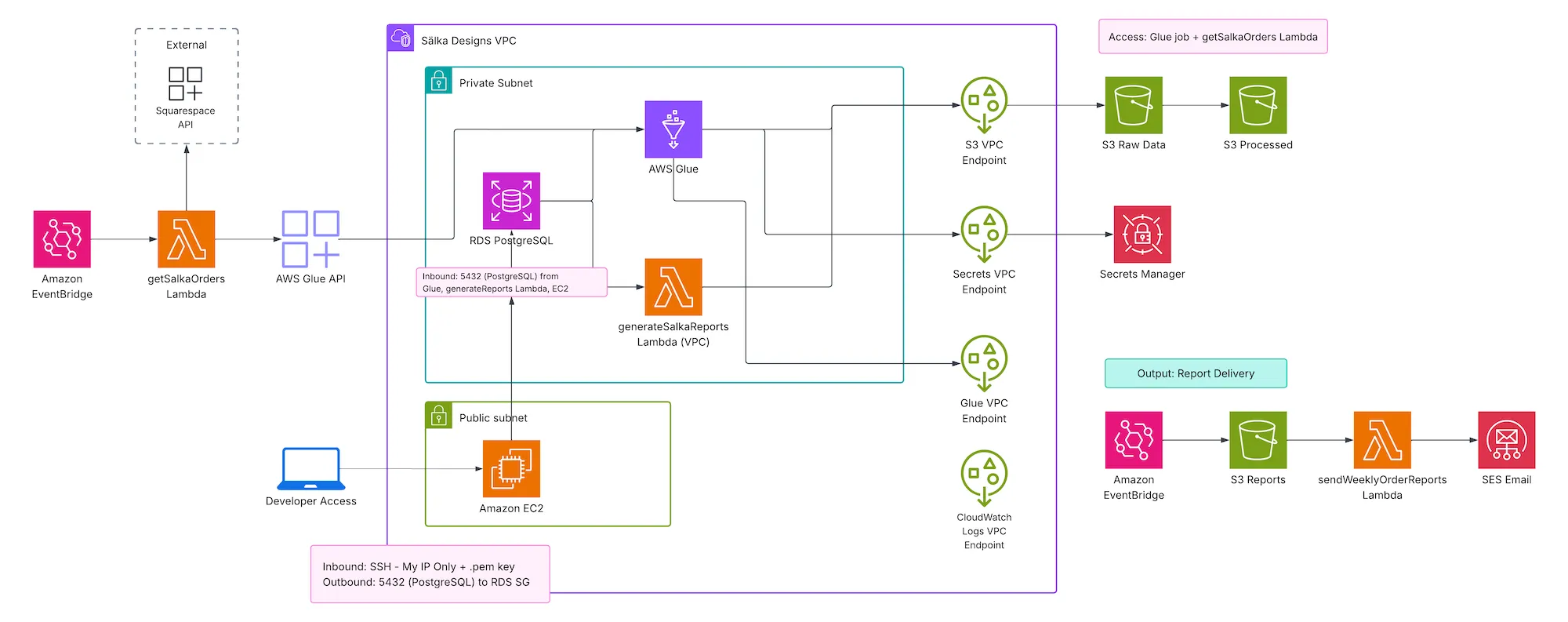
Given the sensitive nature of customer data, the infrastructure implements strong security standards:
Network Isolation:
- Private subnets for RDS with no public internet access
- VPC endpoints for direct AWS service access without internet routing
- Multi-AZ setup for high availability
Security Layers:
- Security groups limiting database access to Glue job and report Lambda only
- Bastion server for local development access with SSH key authentication
- Principle of least privilege for all IAM roles
Analytics & Reporting Layer
When ETL processing completes, EventBridge triggers report generation:
def generate_reports():
engine = get_db_connection()
# Report 1: Pending Orders Summary
pending_orders_query = """
SELECT product_sku, product_name, product_color, sum(product_quantity) AS quantity
FROM orders o
JOIN order_items oi ON o.order_id = oi.order_id
WHERE lower(fulfillment_status) = 'pending'
GROUP BY product_sku, product_name, product_color
"""
# Report 2: Bill of Materials (Cut List)
cut_list_query = """
SELECT
bom.material_piece, bom.material_color,
SUM(bom.material_quantity * oi.product_quantity) AS total_material_needed
FROM orders o
JOIN order_items oi ON o.order_id = oi.order_id
JOIN bill_of_materials bom ON oi.product_sku = bom.product_sku
WHERE lower(o.fulfillment_status) = 'pending'
GROUP BY bom.material_piece, bom.material_color
"""
# Create Excel with multiple sheets
with pd.ExcelWriter(excel_path, engine='xlsxwriter') as writer:
pending_orders_df.to_excel(writer, sheet_name='Pending Orders', index=False)
cut_list_df.to_excel(writer, sheet_name='Materials Cut List', index=False)Automated Email Delivery:
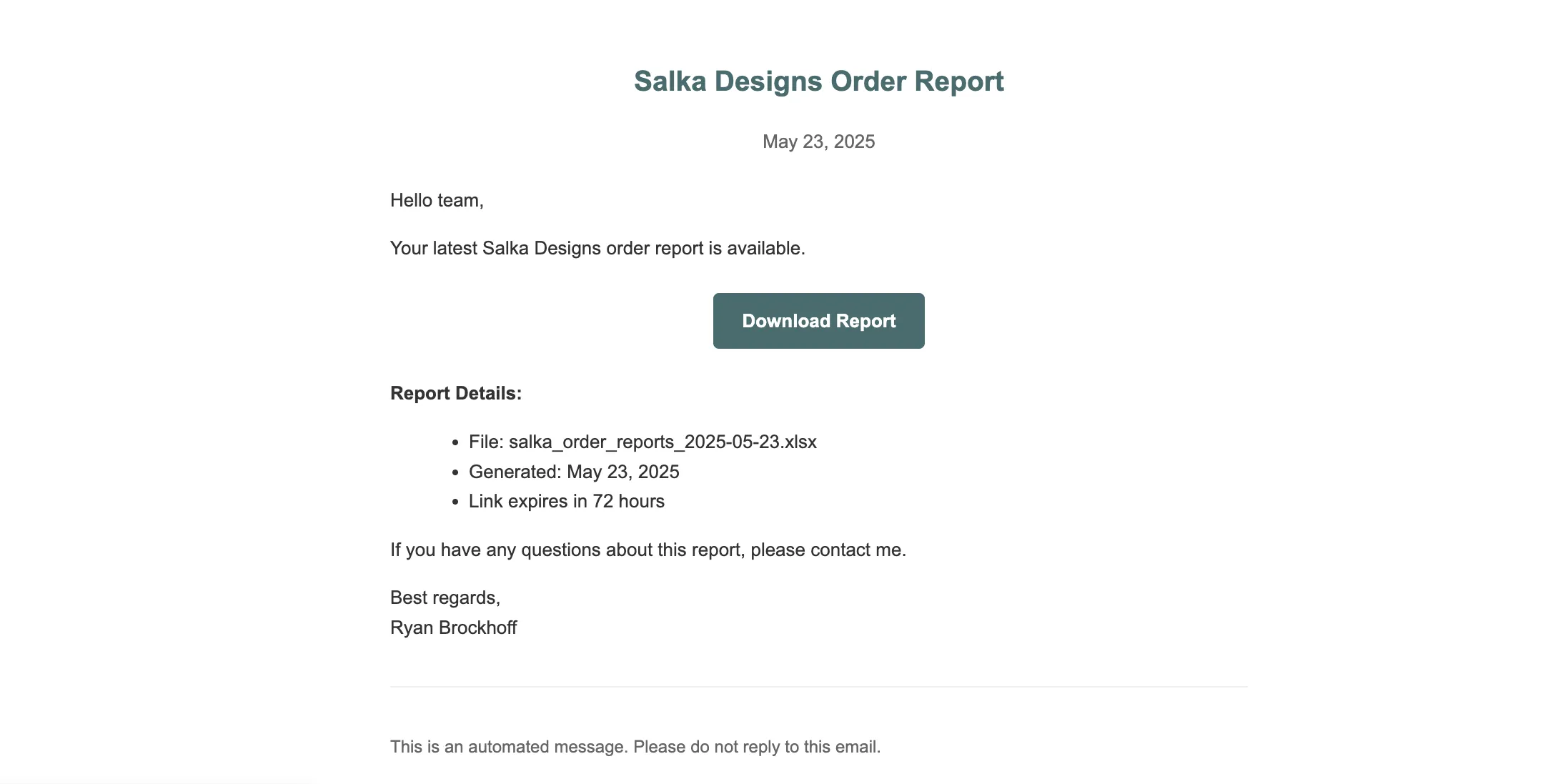
When reports are saved to S3, an event triggers email delivery with a presigned URL (72-hour expiration) for secure file access.
Results & Business Impact
Automation Achievements:
- Eliminated 3-5 hour weekly manual process
- Reports delivered automatically every Monday morning
- System handles growing order volume without modification
Business Value:
- Production Planning: Automated order schedule improves efficiency
- Inventory Management: BOM enables proactive procurement
- Fulfillment Accuracy: Pending orders report prevents missed shipments
Cost Optimization
VPC endpoints don’t need to run 24/7 for a weekly pipeline. A future optimization involves Lambda functions for endpoint creation/teardown scheduled around pipeline runs.
| Configuration | Monthly Cost | Annual Cost |
|---|---|---|
| Multi-AZ (24/7) | $58.41 | $700.92 |
| Single AZ (24/7) | $29.21 | $350.52 |
| Automated (2 hr/week) | $0.64 | $7.68 |
Potential Annual Savings: $343-$693 depending on configuration